반응형
Content
- Data
Data qualityExploratory data analysis
Numerical summaryGraphical summary
1. DATA
1.1 Data Terminology
- 데이터 샘플과 그 특성의 집합(Collection of data samples and their features)
- 데이터 샘플은 관찰이나 측정을 통해 얻은 정보의 단위를 말함.
- 이러한 데이터 샘플들의 집합을 가지고 분석하거나 학습하는 데 사용.
- 각 샘플은 여러 가지 특성(또는 속성)을 가질 수 있다.
- 특성의 집합이 샘플을 설명( A feature or an attribute is a property or characteristic of a sample )
- 한 샘플은 여러 개의 특성을 조합하여 설명될 수 있다.
- 이러한 특성들의 집합은 샘플의 전체적인 모습을 이해하는 데 도움.
- 데이터 분석이나 머신러닝에서는 이러한 특성들을 기반으로 샘플들을 분류하거나 예측하는 모델을 만듬.
- 특성 또는 속성( A collection of features describe a sample)
- 특성(또는 속성)은 샘플의 특정한 성질이나 특징을 나타내는 데이터 요소.
- 예를 들어, 사람에 대한 데이터 샘플에서 '키', '몸무게', '나이' 등이 각각의 특성이 될 수 있다.
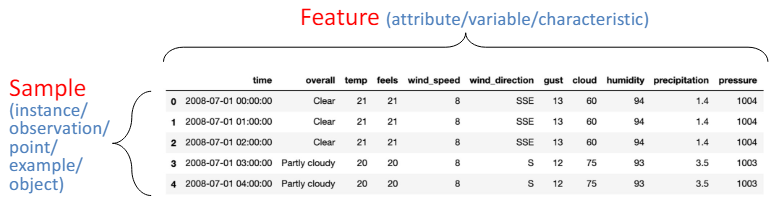
1.2 Data in a tabular format
- Tabular data (structured data, 정형데이터)
- 정형 데이터는 데이터가 열과 행으로 구성된 표 형식으로 정리되어 있는 데이터를 의미.
- 이는 가장 일반적인 데이터 형식 중 하나( The most common form )
- 데이터베이스, 엑셀 시트, CSV 파일 등에서 흔히 볼 수 있다.
- 각 열은 특정한 속성(또는 '필드')을 나타내며, 각 행은 데이터 레코드나 샘플을 나타냄.
- 반면에 비정형 데이터(non-tabular data)
- 표 형식으로 쉽게 정리할 수 없는 모든 데이터 유형을 말함.
- 텍스트 데이터: 소셜 미디어 게시물, 이메일, 문서 등 자유 형식의 텍스트
- 이미지 및 비디오 데이터: 사진, 영상 등 시각적 콘텐츠
- 오디오 데이터: 음성 녹음, 음악 파일 등
- 로그 파일: 시스템 로그, 웹 서버 로그 등
- 이러한 비정형 데이터는 구조화된 데이터베이스에 넣기 어렵거나 불가능
- 처리와 분석을 위해서는 특별한 기술과 도구가 필요
- 표 형식으로 쉽게 정리할 수 없는 모든 데이터 유형을 말함.
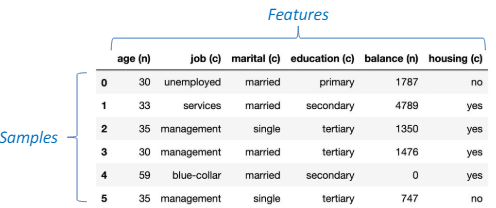
1.3 Example: Iris Dataset
- How many features? m = 4
- 꽃받침 길이(sepal length)
- 꽃받침 너비(sepal width)
- 꽃잎 길이(petal length)
- 꽃잎 너비(petal width)
- How many samples? n = 50
- 샘플(n): 데이터셋에서 개별 기록이나 엔티티.
- 각 행은 샘플을 대표클래스
- Class label(y)
- 데이터 샘플이 속하는 범주나 클래스를 나타내는 것으로, 특정 분류 문제에서의 예측 대상.
- 이 클래스 라벨은 데이터 샘플의 특성(feature)이 아니라, 해당 샘플이 속하는 그룹이나 분류를 나타내는 '결과 값'이나 '타겟 변수'.
- 즉, 머신러닝에서는 이 클래스 라벨을 사용하여 모델을 학습시켜, 새로운 데이터 샘플의 특성을 바탕으로 해당 샘플이 어떤 클래스에 속할지를 예측.
- 따라서 클래스 라벨은 데이터 셋에서 샘플의 특성을 설명하는 것이 아니라, 각 샘플이 어떤 결과에 해당하는지를 나타내는 정보이기 때문에 특성(feature)에 포함시키지 않음.
- 머신러닝 모델에서는 이러한 클래스 라벨을 기반으로 학습하고, 특성들을 사용해 라벨을 예측하는 방식으로 작동.

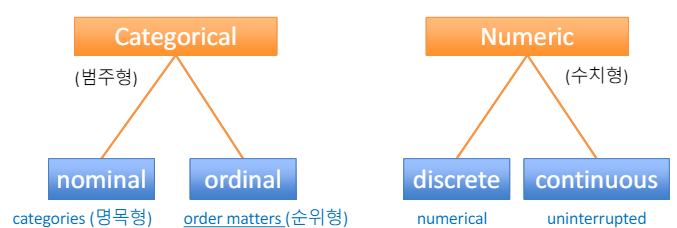
1.4 Types of Variables
- 변수의 유형에는 크게 범주형(categorical)과 수치형(numeric) 변수가 있다.
- 범주형 변수(Categorical Variables) : 명목형(Nominal) & 순위형(Ordinal)
- 명목형(Nominal): 명목형 변수는 순서나 등급을 나타내지 않음. (No relation is implied among nominal values
- 예를 들어, 혈액형(A, B, O, AB), 성별(남성, 여성)과 같이 서로 구별되는 범주나 그룹으로 분류할 수 있지만, 이들 사이에는 상위나 하위, 더 중요하거나 덜 중요하다는 개념이 없다.
- 순위형(Ordinal): 순위형 변수는 명목형 변수와 마찬가지로 범주로 구성되지만, 범주 간에는 명확한 순서나 등급이 있다.
- 예를 들어, 학점(A>B>C>D>F), 만족도 조사(매우 만족 > 만족 > 보통 > 불만족 > 매우 불만족)가 이에 해당합니다. 서열형 변수는 순서의 개념이 있기 때문에, 데이터 분석 시 이러한 순서 정보를 활용할 수 있다.
- 명목형(Nominal): 명목형 변수는 순서나 등급을 나타내지 않음. (No relation is implied among nominal values
- 수치형 변수(Numeric Variables) : 이산형(Discrete) & 연속형(Continuous)
- 이산형(Discrete): 이산형 변수는 정수( Integer representation )로 표현됨.
- 예를 들어, 사람의 수, 책의 수처럼 셀 수 있는 값이 해당. 이산형 변수는 일반적으로 셀 수 있는 범위 내에서만 값을 가짐.
- 연속형(Continuous): 연속형 변수는 실수( Real numbers )로 표현, 일정 범위 안에서 어떤 값이든 가질 수 있다.
- 예를 들어, 키, 몸무게, 온도와 같은 측정값이 이에 해당. 연속형 변수는 끊임없이 변할 수 있는 값을 나타냄.
- 이산형(Discrete): 이산형 변수는 정수( Integer representation )로 표현됨.
- 명목형과 순위형 변수 간의 구분은 항상 명확하지 않을 수 있다. 때로는 데이터의 맥락이나 분석의 목적에 따라, 같은 데이터를 명목형으로 볼지 서열형으로 볼지 결정될 수 있다.
- 예를 들어, "매우 만족, 만족, 보통, 불만족, 매우 불만족"과 같은 만족도 조사의 응답을 단순히 다른 범주로만 보고 순서를 고려하지 않을 수도 있고, 반대로 순서에 따른 중요성을 고려하여 분석할 수도 있다.
1.5 Why is this important?
- 변수의 유형을 이해하는 것은 중요.
- 많은 모델들은 데이터가 특정 형태( Many models require data to be represented in a specific form ), 예를 들어 실수 벡터 형태( real-valued vectors )로 표현되기를 요구하기 때문.
- 실수가 아닌 값( non-real valued inputs )을 입력으로 사용할 때, 우리는 어떻게 해야 할까?
- 명목형 변수가 M개의 값으로 구성된 경우: M개의 값에 1부터 M까지 순차적으로 매핑하는 것은 적절하지 않다.
- 이유는 이러한 매핑이 변수 사이에 존재하지 않는 순서나 중요도를 부여할 수 있기 때문.
- 예를 들어, 색상 '빨강', '파랑', '녹색'을 각각 1, 2, 3으로 매핑한다고 할 때, 이 숫자들은 실제로는 색상 사이의 어떠한 순서나 중요도를 나타내지 않음.
- 원-핫 인코딩 사용: 이러한 문제를 해결하기 위해 '원-핫 인코딩(One-Hot Encoding)' 기법을 사용할 수 있다.
- 원-핫 인코딩은 각 카테고리를 독립적인 이진 변수로 변환하는 방법.
- 예를 들어, 세 가지 색상 '빨강', '파랑', '녹색'을 원-핫 인코딩으로 표현하면, '빨강'은 [1, 0, 0], '파랑'은 [0, 1, 0], '녹색'은 [0, 0, 1]과 같이 표현됨.
- 이 방식은 각 카테고리가 서로 독립적임을 명확하게 하며, 모델이 카테고리 간의 임의의 순서나 중요도를 부여하는 것을 방지.
- 명목형 변수가 M개의 값으로 구성된 경우: M개의 값에 1부터 M까지 순차적으로 매핑하는 것은 적절하지 않다.
1.6 범주형 데이터 표현
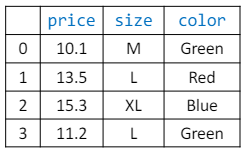
- 범주형 데이터를 표현할 때, 특히 명목형 데이터를 처리하는 방법에는 여러 가지가 있다.
- 예로, T-셔츠의 사이즈와 색상 데이터를 들 수 있다. 사이즈는 'M < L < XL'과 같이 순서가 있어서 서수형 데이터로 간주할 수 있으며, 색상은 'blue, green, red'와 같이 순서가 없어 명목형 데이터로 봄.
- 옵션 1: 정수로 매핑하는 방법
- 예를 들어, 색상을 'blue: 0, green: 1, red: 2'와 같이 정수로 매핑할 수 있다. 이 방법은 데이터를 간단히 숫자로 변환할 수 있다는 장점이 있지만, 중요한 문제점이 있다.
- 문제점: 알고리즘이 이 값을 수치형 데이터로 간주하게 되면, 색상 간에 수치적인 관계나 순서가 있다고 잘못 해석할 수 있다.
- 예를 들어, 'green'은 'blue'보다 크고 'red'는 'green'보다 크다고 모델이 해석할 수 있는데, 실제로는 색상 간에 이러한 수치적인 관계나 순서가 존재하지 않음.
- 이로 인해 데이터의 실제 의미를 잘못 해석하여 기대하지 않은 결과나 최적이 아닌 결과를 초래할 수 있다.
- 따라서 이러한 명목형 데이터를 처리할 때는 정수 매핑보다는 'One-Hot Encoding'과 같은 다른 방법을 사용하는 것이 더 적절할 수 있다.
- One-Hot Encoding은 각 범주를 독립적인 이진 변수로 변환하여, 알고리즘이 각 범주를 독립적으로, 그리고 올바르게 해석할 수 있도록 도움.
1.7 One-hot encoding
- One-hot encoding은 범주형 데이터를 다루는 표준적인 방법(Standard approach for categorical data)
- 이 방법을 통해 각 범주형 값을 나타내기 위해 이진 벡터(binary vector)를 생성(Create a binary vector to represent each categorical value)
- 이는 범주형 데이터의 표현을 더욱 풍부하게 만든다. (Allows the representation of categorical data to be more expressive)
- 예를 들어, 색상이 'blue', 'green', 'red'의 세 가지 범주를 가지고 있다고 가정. One-hot encoding을 사용하면 각 색상은 다음과 같이 이진 벡터:
- 'blue': [1, 0, 0]
- 'green': [0, 1, 0]
- 'red': [0, 0, 1]
- 각 벡터의 위치는 특정 색상을 나타내며, 해당 색상에 해당하는 위치는 1로, 그 외는 모두 0으로 표시됨.
- 이 방식을 통해, 각 범주 값은 서로 독립적으로 표현되며, 알고리즘이 이들 간의 잘못된 수치적 관계를 추론하는 것을 방지할 수 있다.
- 예를 들어, 색상이 'blue', 'green', 'red'의 세 가지 범주를 가지고 있다고 가정. One-hot encoding을 사용하면 각 색상은 다음과 같이 이진 벡터:
- One-hot encoding은 모델이 범주형 데이터를 더 정확하게 이해하고 처리할 수 있게 하므로, 복잡한 데이터 세트에서 유용하게 사용됨.
- 하지만 범주의 수가 매우 많을 경우, 벡터의 차원이 커져서 데이터의 차원이 커질 수 있다는 단점도 있다.
- 이러한 문제를 해결하기 위해 차원 축소 기법이나 임베딩(embedding) 기법 등을 사용하기도 함.

반응형
'Computer Science > 기계학습' 카테고리의 다른 글
| [Classification 1] 2. Data split in supervised learning (0) | 2024.04.21 |
|---|---|
| [Classification 1] 1. Introduction to supervised learning approach (0) | 2024.04.21 |
| [Exploratory Data Analysis] 3. Exploratory data analysis (2) (0) | 2024.04.21 |
| [Exploratory Data Analysis] 3. Exploratory data analysis (1) (0) | 2024.04.21 |
| [Exploratory Data Analysis] 2. Data quality (0) | 2024.04.20 |



